
* 저는 머신러닝/딥러닝에 관해 공부하고 있는 사람입니다.
잘못된 내용이나 참고할 만한 내용이 있다면 댓글로 남겨주시면 정말 감사드리겠습니다!
머신러닝/딥러닝 모델을 만들기 위해서는
학습 데이터를 '적절한 형태'로 가공해야한다.
여기서 '적절한 형태'란, 사용하는 모델에 따라 다르다.
내가 사용할 모델은 다층 퍼셉트론(MLP)이다.
MLP의 학습데이터는 다음과 같은 조건을 만족해야한다.
"정규화한 1차원배열"
그래서 이번 포스팅에서는 이미지데이터(X data)와 카테고리데이터(y data)를
정규화한 1차원배열로 만드는 방법에 대해서 다룬다.
저번 포스팅에서 X_train, X_test, Y_train, Y_test 데이터를 다운로드 받았다.
하나씩 살펴보겠다.
1. X 데이터 (이미지 데이터)
X_train

shape 명령어를 사용하면 데이터 형식을 더 쉽게 파악할 수 있다.
X_train.shape

(데이터 수, 세로, 가로, RGB 색공간) 순으로 출력한다.
총 데이터 수는 50000개 이고,
RGB 색공간을 가진 32 * 32 픽셀짜리 3차원 데이터임을 알 수 있다.
대표 사진 하나를 살펴보자.
plt.figure
plt.imshow(X_train[0])
plt.colorbar()
plt.grid(False)
plt.show()
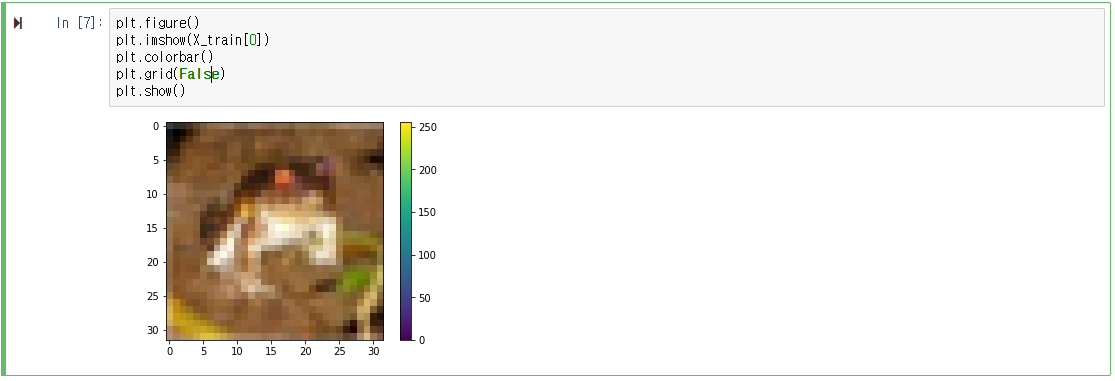
좌측과 아래쪽 눈금을 보면 크기가 32*32인 것을 확인할 수 있다.
우측의 컬러바는 한 픽셀이 가질 수 있는 값을 나타내는데 0~255사이의 값을 가질 수 있다고 보인다.
정리하면 X_train 데이터는
3차원 배열 형식이고, 정규화되지 않았다.
그래서 내가 해야할 일은
① 3차원 배열 → 1차원 배열
② 정규화(0~1사의 값으로 만들어주기)
① 3차원 배열 → 1차원 배열
reshape함수를 사용하면 차원축소를 할 수 있다.
첫 번째 인자에 -1을 넣어주면 1차원 배열로 차원 축소된다.
X_trian = X_train.reshape(-1, 32*32*3)

2. 정규화
정규화를 위해서는 각 데이터들을 해당 데이터 셋이 가질 수 있는 값의 범위로 나눠주면 된다.
X_train의 경우 한 픽셀이 0~255사이의 값을 가질 수 있으므로 255로 나눠준다.
X_tain = X_train.reshape(-1, 32*32*3)/255

출력 결과를 보면 각 데이터가 정규화된 1차원 배열로 변환되었음을 확인할 수 있다.
2. y 데이터 (레이블 데이터)
y_train 데이터를 살펴보자.
len(y_train)

X_train 데이터와 마찬가지로 데이터 수는 50000개이다.
좀 더 자세히 살펴보면,
y_train

각 데이터가 배열이 아닌 데이터(0차원(?))임을 알 수 있다.
y 데이터는 X 데이터가 어떤 사진인지, 그 카테고리를 뜻하는 데이터이기 때문에
위와 같은 형식을 갖는다.
각 레이블 값은 다음을 의미한다. (이전 포스팅 참조)
labels = ["airplane","automobile","bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
나는 이 데이터들을 각각 정규화한 1차원 배열 형식으로 바꿔야 한다.
이런 카테고리 데이터를 정규화한 1차원 배열로 바꾸는 방법 중 하나는
one-hot vector 형식으로 바꾸는 것이다.
one-hot vector로 바꾸기
one-hot vector란 하나만 High(1) 상태이고, 다른 것은 Low(0) 상태인 데이터를 말한다.
예를 들어, 'airplane'은 [1,0,0,0,0,0,0,0,0,0], 'automobile'은 [0,1,0,0,0,0,0,0,0,0]
그리고 'truck'는 [0,0,0,0,0,0,0,0,0,1] 으로 표현할 수 있다.
tensorflow모듈 중 하나인 keras에서 제공하는 to_categorical 함수를 사용하면 손쉽게 바꿀 수 있다.
첫 번째 인자는 바꾸고자 하는 데이터셋을, 두 번째 인자에는 레이블 수를 입력하면 된다.
import keras
y_train = keras.utils.to_categorical(y_train, 10)

출력 결과를 보면 각 데이터가 정규화된 1차원 배열 형식임을 알 수 있다.
자, 이상으로 train셋에 대한 데이터 전처리는 끝났다.
X_test 와 y_test 데이터도 동일하게 변경해주자.
X_test = X_test.reshape(-1,32*32*3)/255
y_test = keras.utils.to_categorical(y_test, 10)

이상으로 다층퍼셉트론을 위한 데이터 전처리는 마쳤다.
다음 포스팅에서는 다층 퍼셉트론 모델을 정의 및 컴파일하고,
학습을 수행하는 내용에 대해 포스팅하겠다.
Reference.
https://www.tensorflow.org/tutorials/keras/classification
https://www.cs.toronto.edu/~kriz/cifar.html
CIFAR-10 and CIFAR-100 datasets
< Back to Alex Krizhevsky's home page The CIFAR-10 and CIFAR-100 are labeled subsets of the 80 million tiny images dataset. They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. The CIFAR-10 dataset The CIFAR-10 dataset consists of 60000
www.cs.toronto.edu
'Deep Learning > [Books] 머신러닝, 딥러닝 실전 앱 개발' 카테고리의 다른 글
| 딥러닝 모델 평가 & 모델 저장하기 (3) | 2020.05.11 |
|---|---|
| 딥러닝 모델 생성, 컴파일 그리고 학습시키기 (0) | 2020.05.07 |
| 학습 데이터 확보하기 (3) | 2020.04.30 |
| Anaconda 가상환경 세팅 및 Tensorflow 설치 (16) | 2020.04.27 |
| Anaconda 설치하기 (0) | 2020.04.23 |