
이번 포스팅에서는 기본적인 데이터탐색에 사용할 수 있는 파이썬 명령어 3가지를 다룬다.
우선, 예시에서 사용할 데이터를 세팅해보자.
사이킷런에서 제공하는 당뇨병 환자의 데이터 세트를 로드해서 사용하겠다.
로드한 데이터 셋은 diabetes라는 변수에 저장했다.
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
| 1. numpy 배열의 shape 속성
머신러닝에서는 데이터를 넘파이 배열로 저장하는 경우가 많다.
넘파이 배열의 shape 속성은 배열의 크기 정보를 담고있다.
배열의 크기정보를 통해서 우리는 데이터 세트에서 샘플의 개수와 특성의 수를 파악할 수 있다.
샘플이란 데이터 1 세트를 의미하고, 특성이란 한 샘플의 여러 특징을 의미한다.
예시를 통해서 자세히 살펴보자.
load_diabetes()를 사용하면 데이터를 저장한 변수의 data속성과 target 속성에
각각 입력과 타깃 데이터가 넘파이 배열 형태로 저장된다.
shape 속성을 사용해서 배열의 크기를 확인해보자.
print(diabetes.data.shape, diabetes.target.shape)
# 결과 : (442,10) (442,)
data는 442 * 10 크기의 2차원 배열이고, target은 442개의 요소를 가진 1차원 배열이다.
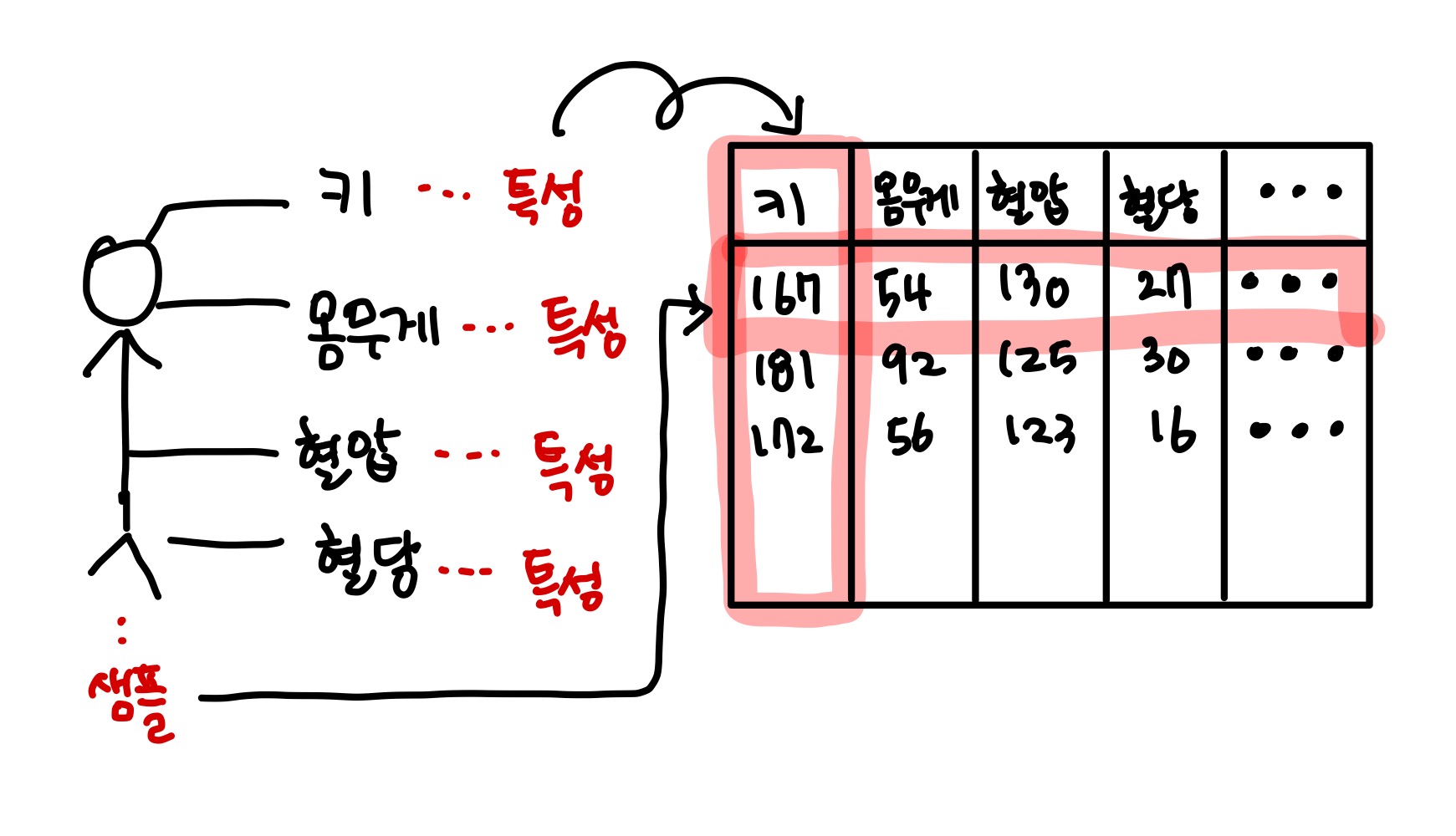
그림으로 나타내면 아래와 같다.

diabetes.data를 보면 442개의 행과 10개의 열로 구성되어 있다.
여기서 행은 샘플(sample)이고, 열은 샘플의 특성(feature)이다.
샘플이란 당뇨병 환자에 대한 특성으로 이루어진 데이터 1세트를 의미하고,
특성은 당뇨병 데이터의 여러 특징들을 의미한다.
쉽게 말해서 당뇨병 데이터에는 환자의 혈압, 혈당, 몸무게, 키 등의 특징(즉, 특성)이 있는데,
그 특징들의 수치를 모아 1세트로 만들면 1개의 샘플이 나온다고 보면 된다.
| 2. : (슬라이싱)
배열에서 요소를 출력하기 위해서는 아래와 같이 [] 안에 출력하고자 하는 요소의 행,열 인덱스를 지정한다.
diabetes.data[2,3] // 2번째 샘플의 3번째 특성
# 결과 : -0.00567061055493425
: (슬라이싱)을 사용하면 인덱스를 범위형태로 지정할 수 있다.
주의할 점은 우측에 지정한 (인덱스-1) 번째까지 출력된다는 점이다.
예를 들어 data 배열에서 0 ~ 2번째 샘플을 출력하고 싶으면 0 : 3 으로 작성해야한다.
diabetes.data[0:3]
# 결과 :
# array([[ 0.03807591, 0.05068012, 0.06169621, 0.02187235, -0.0442235 ,
# -0.03482076, -0.04340085, -0.00259226, 0.01990842, -0.01764613],
# [-0.00188202, -0.04464164, -0.05147406, -0.02632783, -0.00844872,
# -0.01916334, 0.07441156, -0.03949338, -0.06832974, -0.09220405],
# [ 0.08529891, 0.05068012, 0.04445121, -0.00567061, -0.04559945,
# -0.03419447, -0.03235593, -0.00259226, 0.00286377, -0.02593034]])
0 ~ 3번째 샘플의 2~4번째 특성을 살펴보기 위해서는 아래와 같이 지정하면 된다.
diabetes.data[0:3, 2:5]
# 결과 :
# array([[ 0.06169621, 0.02187235, -0.0442235 ],
# [-0.05147406, -0.02632783, -0.00844872],
# [ 0.04445121, -0.00567061, -0.04559945]])
타깃데이터도 살펴보자.
첫번째 요소부터 추출하면 첫번째 인덱스는 생략해도 된다.
diabetes.target[:3]
# 결과 : array([151., 75., 141.])
슬라이싱 문법을 정리하면 아래와 같다.
배열명[ 행(샘플)의 시작인덱스 : 종료인덱스 + 1, 열(특성)의 시작인덱스 : 종료인덱스 + 1 ]
대개 머신러닝용 데이터는 샘플과 특성의 수가 많아서 직관적으로 데이터를 확인하기 어려울 때가 많다.
슬라이싱을 사용하면 원하는 부분만 잘라서 볼 수 있기 때문에 데이터를 탐색하는데 도움을 받을 수 있다.
| 3. scatter()
데이터를 탐색하는데 유용한 방법 중 하나가 그래프를 그려보는 것이다.
scatter()는 가장 기본적인 그래프 중 하나인 산점도를 그려주는 명령어이다.
* 산점도는 직교좌표계를 이용하여 두 개의 변수 사이의 관계를 나타내는 그래프이다.
당뇨병 데이터 세트에는 10개의 특성이 있으므로 이 특성을 모두 그래프로 표현하려면 3차원 이상의 그래프를 그려야한다.
3차원 이상의 그래프는 그릴 수 없으므로 1개의 특성만 사용하겠다.
여기서는 세 번째 특성과 타깃 데이터로 산점도를 그렸다.
import matplotlib.pyplot as plt
plt.scatter(diabetes.data[:,2], diabetes.target)
plt.xlabel('x')
plt.ylabel('y')
plt.show()

x축은 data의 세번째 특성이고, y축은 타깃데이터이다.
이 그래프를 보면 세번째 특성과 타깃데이터 사이에 정비례 관계가 있음을 알 수 있다.
이렇게 각 특성과 타깃데이터 사이의 관계를 파악해두고 머신러닝 모델 선택 단계에서 활용할 수 있다.
'Deep Learning > [Books] Do it! 정직하게 코딩하며 배우는 딥러닝 입문' 카테고리의 다른 글
| [모델 선정] 이진분류 알고리즘 3가지 (퍼셉트론, 아달린, 로지스틱 회귀) (2) | 2020.07.09 |
|---|---|
| [모델 구축] 선형회귀 알고리즘 구현하기 (전체 소스코드 첨부) (3) | 2020.07.06 |
| [모델 구축] 경사하강법을 구현하는 방법 - ② 손실함수 미분하기 (7) | 2020.06.29 |
| [모델 구축] 경사하강법을 구현하는 방법 - ① 직접 변화율 계산하기 (9) | 2020.06.25 |
| 6. 머신러닝/딥러닝 '지도학습'의 목표 2가지 - 회귀와 분류 (2) | 2020.06.22 |