
이번 포스팅에서는 keras를 사용하여 다중분류 신경망을 구현해본다.
Keras
Keras는 딥러닝 패키지를 편리하게 사용하기 위해 만들어진 래퍼(Wrapper) 패키지이다. 래퍼(Wrapper)는 자바에서는 기본 자료형을 객체형으로 바꿔주는 클래스들을 의미하는데, 파이썬에는 정확히 무엇을 의미하는지 모르겠다.. 한 블로그에서는 Keras를 Tensorflow 라이브러리의 일종이라고 설명하기도 한다. 어쨋든 Keras는 사용자가 Tensorflow를 좀 더 쉽게 사용할 수 있도록 만들어놓은 패키지인 것 같다.
Wrapper Class in JAVA
www.tcpschool.com/java/java_api_wrapper
코딩교육 티씨피스쿨
4차산업혁명, 코딩교육, 소프트웨어교육, 코딩기초, SW코딩, 기초코딩부터 자바 파이썬 등
tcpschool.com
Tensorflow vs Keras
blog.naver.com/PostView.nhn?blogId=magnking&logNo=221164330101
Tensorflow VS Keras
둘은 무슨 사이이냐?Tensorflow는 잘 알려진 것처럼 구글에서 개발하고 오픈소스로 공개한 머신러닝 라이...
blog.naver.com

Keras는 인공신경망 모델을 만들기 위한 Sequential 클래스와 완전 연결층을 만들기 위한 Dense 클래스를 제공한다. Sequential 클래스는 '순차적으로 층을 쌓은 신경망 모델'이고, Dense 클래스는 모델에 포함된 완전 연결층이다. 즉 은닉층과 출력층을 Dense 클래스의 객체로 구성하고, 각각의 객체를 Seqeuntial 클래스 객체에 추가하여 다중분류 신경망을 구현한다.
How to use ?
1. Sequential
Sequential 객체에 Dense 객체를 추가하는 방법은 2가지가 있다.
① Sequential 객체를 생성할 때 층을 추가하는 방법
신경망 모델에 추가할 층을 파이썬 리스트로 만들어 전달한다.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([Dense(...),...])
② 객체를 생성한 후 add() 메소드를 사용하여 층을 추가하는 방법
model = Senquential()
model.add(Dense(...))
model.add(Dense(...))2. Dense
① 첫 번째 파라미터 : 층의 유닛 개수
Dense(unit =100,...)
② 두 번째 파라미터 : 활성화함수
Dense(100, activation='sigmoid')
기본값은 None이므로 따로 지정하지 않으면 활성화함수가 적용되지 않는다. sigmoid 외에 소프트맥스 함수(softmax), 하이퍼볼릭 탄젠트 함수(tanh), 렐루 함수(relu) 등이 있다.
③ input_shape
Dense(100, activation='sigmoid', input_shape=(784,))
첫 번째 은닉층에는 input_shape 매개변수에 입력 데이터의 크기를 지정해야한다. 입력 행렬의 첫 번째 차원은 입력데이터의 개수이기 때문에 나머지 차원만 튜플 형태로 입력한다.
3. 최적화함수와 손실함수 설정
최적화함수와 손실함수는 Sequential 클래스의 compile() 메소드를 사용하여 지정한다.
① 최적화함수
model.compile(optimizer='sgd',...)
최적화 알고리즘의 매개변수명은 optimizer로 'sgd'를 지정하면 기본 경사 하강법을 최적화 알고리즘으로 사용한다. 이때 학습률은 0.01이다.
② 손실함수
model.compile(optimizer='sgd', loss='categorical_crossentropy')
손실함수의 매개변수명은 loss이다. 제곱오차의 경우에는 'mse', 로지스틱 손실함수는 'binary_crossentropy' 그리고 크로스 엔트로피 손실함수는 'categorical_crossentropy'로 지정하여 사용한다.
③ metrics
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
metrics 매개변수는 훈련과정을 기록하는 지표를 지정하는 매개변수이다. 모델을 훈련하며 기록한 정보를 History객체에 담아 반환한다. 아무것도 지정하지 않으면 기본값으로 손실값(loss)만 기록된다. 'accuracy' 를 추가하면 정확도에 대한 기록도 확인할 수 있다.
History객체는 history 딕셔너리에 여러 측정 지표를 담고 있다. history 딕셔너리의 키를 출력해보면 어떤 측정지표가 들어있는지 알 수 있다.
print(history.history.keys())
# dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
훈련세트와 검증세트의 손실의 나타내는 loss, val_loss와 정확도를 나타내는 accuracy, val_accuracy가 있다.
Practice
load & Preprocess Data
import tensorflow as tf
(x_train_all, y_train_all) , (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
class_names = ['티셔츠/윗도리','바지','스웨터','드레스','코트','샌들','셔츠','스니커즈','가방','앵글부츠']
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(x_train_all, y_train_all, stratify=y_train_all, test_size=0.2, random_state=42)
# x 전처리
x_train = x_train /255
x_val = x_val / 255
x_train = x_train.reshape(-1,784)
x_val = x_val.reshape(-1,784)
# y 전처리
y_train_encoded = tf.keras.utils.to_categorical(y_train)
y_val_encoded = tf.keras.utils.to_categorical(y_val)
Define Model
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])Fit Model
history = model.fit(x_train, y_train_encoded, epochs=40, validation_data=(x_val, y_val_encoded))Loss & Accuracy Graph
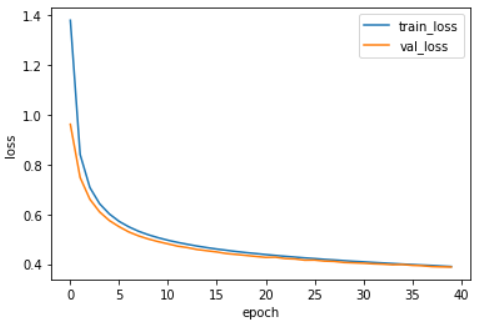
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train_loss','val_loss'])
plt.show()
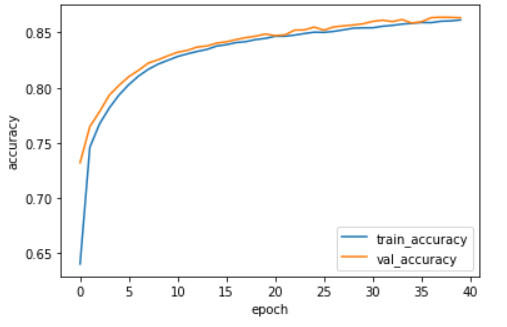
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train_accuracy','val_accuracy'])
plt.show()
Evaluate Model
loss, accuracy = model.evaluate(x_val, y_val_encoded, verbose=0)
print(accuracy)
# 0.8634166717529297
정확도는 86%정도로 사이킷런으로만 구현한 신경망 보다는 높은 성능을 낸 것을 확인할 수 있었다. 하지만 이 정도 성능도 실전에서 사용하기에는 무리가 있다. 성능이 뛰어나게 향상되지 않은 이유는 여기서 구현한 모델이 이미지 데이터에 잘 맞는 모델이 아니기 때문이다. 다음 포스팅에서는 이미지 분류에 효과적인 합성곱 신경망에 대해서 살펴본다.
끝.
Reference.
도서 <Do it! 정직하게 코딩하며 배우는 딥러닝 입문> 이지스 퍼블리싱, 박해선 지음
'Deep Learning > [Books] Do it! 정직하게 코딩하며 배우는 딥러닝 입문' 카테고리의 다른 글
| 합성곱 신경망 - 합성곱 연산과 교차상관 연산 (0) | 2020.11.12 |
|---|---|
| [모델 구축] 사이킷런 SGDClassifier 클래스 (1) | 2020.10.31 |
| 다중분류 다층신경망 구현하기 - 하 (1) | 2020.10.29 |
| 다중분류 다층신경망 구현하기 - 상 (0) | 2020.10.19 |
| 미니배치경사하강법을 이용하는 로지스틱 회귀 모델 구현하기 (0) | 2020.10.15 |